

Usando TensorFlow Object Detection API para detectar peatones y medir la distancia social entre ellos.

Hoy, por desgracia, todo el mundo está familiarizado con el término «distancia social». Es algo con lo que tendremos que vivir por un tiempo hasta que todo vuelva a la normalidad. En Immune Technology Institute hemos desarrollado una aplicación usando TensorFlow Object Detection API para identificar y medir la distancia social entre peatones a tiempo real.
Un momento… ¿Qué es TensorFlow Object Detection API?
TensorFlow Object Detection API es un framework para crear redes neuronales enfocadas a problemas de detección de objetos. Contiene algunos modelos pre-entrenados en distintos conjuntos de datos y que pueden ser utilizados en diversos casos de uso.

Además, este framework puede ser utilizado para aplicar transfer learning a modelos pre-entrenados, lo cual nos permite personalizar dichos modelos para predecir otros objetos. Por ejemplo, podemos aplicar transfer learning a un modelo y usarlo para identificar si una persona lleva mascarilla o no.
La teoría detrás del transfer learning es que si un modelo se entrena en un conjunto de datos lo suficientemente grande y general, este modelo podría ser utilizado como un modelo genérico. Entonces se podría aprovechar las features aprendidas para otros casos de uso sin tener que empezar de cero ni entrenar un nuevo modelo en un nuevo conjunto de datos, lo cual consumiría muchos recursos y tiempo.
En este caso, no necesitamos aplicar transfer learning ya que queremos identificar a los peatones, y ya hay algunos modelos entrenados para ello. En concreto, hemos utilizado el modelo ssd_mobilenet_v2_coco_2018_03_29 que ha sido entrenado para inferir estos objetos:
{
{'id': 1, 'name': u'person'},
{'id': 2, 'name': u'bicycle'},
{'id': 3, 'name': u'car'},
{'id': 4, 'name': u'motorcycle'},
{'id': 5, 'name': u'airplane'},
{'id': 6, 'name': u'bus'},
{'id': 7, 'name': u'train'},
{'id': 8, 'name': u'truck'},
{'id': 9, 'name': u'boat'},
{'id': 10, 'name': u'traffic light'},
...
{'id': 90, 'name': u'toothbrush'}
}Para este caso de uso, sólo necesitamos identificar y mostrar los peatones, por lo que crearemos una función para filtrar las predicciones en base a su etiqueta (label) y sólo mostraremos dichos objetos, person (id=1).
¡Vamos allá! Un poco de código
Cuando desarrollé este código TensorFlow Object Detection API no tenía soporte completo para TensorFlow 2, pero el 10 de julio Google publicó una nueva versión, dando soporte para algunas nuevas funcionalidades. En este caso, he utilizado TensorFlow 1 con la versión r1.13.0 de TF Object Detection API y Google Colab para este experimento.
Puedes encontrar el código en my GitHub.
En primer lugar, necesitamos crear en nuestro Drive el directorio Projects/Pedestrian_Detection, donde clonaremos el repositorio de TensorFlow Object Detection API. Luego, podremos iniciar un notebook con Google Colab.
0_0YsPZGrOb14vQAeP
Primero debemos montar nuestro drive dentro del notebook, simplemente debemos seguir las instrucciones.
from google.colab import drive
drive.mount('/gdrive', force_remount=True)
Posteriormente, podremos cambiar nuestro path a nuestra carpeta raíz Projects/Pedestrian_Detection
%cd /gdrive/'My Drive'/Projects/Pedestrian_Detection/models/research/git clone
https://github.com/tensorflow/models/tree/r1.13.0
¿Por qué he usado esta versión en concreto? ? Básicamente porque al probar otras versiones he encontrado algunos problemas al ejecutarlas, esta es la primera que probé y funcionó perfectamente.
Una vez que hayas clonado el repositorio verás una carpeta llamada Models en el directorio: Projects/Pedestrian_Detection.
Los chicos de TensorFlow son muy majos y nos han proporcionado un notebook para usar un modelo pre-entrenado y detectar objetos en una imagen (lo puedes encontrar en esta ruta: : Projects/Pedestrian_Detection/models/research/object_detection/colab_tutorials). Sin embargo, nosotros vamos a crear nuestro propio notebook porque aprenderemos a implementar nuevas funciones con el objetivo de mejorar la visualización de los objetos predichos.
Crea un nuevo Google Colab en: Projects/Pedestrian_Detection/models/research/object_detection
Lo primero que debemos hacer es cambiar la versión de TensorFlow a la versión 1.x.
%tensorflow_version 1.x
import tensorflow as tf
Como hicimos antes, debemos montar nuestra imagen de drive dentro de Google Colab e ir a la siguiente ruta: Projects/Pedestrian_Detection/models/research/
from google.colab import drive
drive.mount('/gdrive', force_remount=True)
%cd /gdrive/'My Drive'/Projects/Pedestrian_Detection/models/research/
Necesitamos instalar algunas librerias como: Cython, contextlib2, pillow, lxml, matplotlib, pycocotools y protocbuf compiler.
!apt-get install -qq protobuf-compiler python-pil python-lxml python-tk
!pip install -qq Cython contextlib2 pillow lxml matplotlib pycocotools
!pip install tf-slim
!pip install numpy==1.17.0Ahora debemos ejecutar el protoc compiler, el cual es una librería de Google, usada por TensorFlow, para serializar estructuras de datos — es como un XML, pero más ligero, rápido y simple.
Protoc está ya instalado en Google Colab pero si estás usando tu propio ordenador puedes seguir estas instrucciones para instalarlo.
!pwd
!protoc object_detection/protos/*.proto --python_out=.Espera… ¿Qué ha hecho protoc? Básicamente, protoc ha generado un script de Python para cada archivo en /models/research/object_detection/protos.
Guay!! Estamos un poco más cerca ✌️. El siguiente paso es definir algunas variables de entorno como PYTHONPATH e instalar algunos paquetes usando setup.py.
import os
os.environ['PYTHONPATH'] += '/gdrive/My Drive/Projects/Pedestrian_Detection/models/research/:/gdrive/My Drive/Projects/Pedestrian_Detection/models/research/slim/'
!python setup.py build
!python setup.py install
Al final del proceso, deberías ver algo como esto:
Un momento… Necesitamos un modelo, ¿no?… ¡Exacto! Necesitamos descargar un modelo pre-entrenado, en este caso yo he elegido: ssd_mobilenet_v2_coco_2018_03_29 porque es rápido (esto es importante para aplicaciones a tiempo real) y tiene un buen accuracy. Sin embargo, puedes usar otros modelos y analizar su rendimiento. El modelo a elegir vendrá dado por los requerimientos de tu aplicación.
!mkdir /gdrive/'My Drive'/Projects/Pedestrian_Detection/
models/research/pretrained_model
%cd /gdrive/'My Drive'/Projects/Pedestrian_Detection/
models/research/pretrained_model
!wget http://download.tensorflow.org/
models/object_detection/ssd_mobilenet_v2_coco_2018_03_29.tar.gz
!tar -xzf ssd_mobilenet_v2_coco_2018_03_29.tar.gz -C .
%cd /gdrive/'My Drive'/Projects/
Pedestrian_Detection/models/research/Si todo ha funcionado correctamente ya podrás usar TF Object Detection API. El siguiente paso es importar algunas librerías.
import numpy as np
import os
import six.moves.urllib as urllib
import sys
import tarfile
import tensorflow as tf
import zipfile
from distutils.version import StrictVersion
from collections import defaultdict
from io import StringIO
from matplotlib import pyplot as plt
from PIL import Image
# This is needed since the notebook is stored in the object_detection folder.
sys.path.append("..")
from object_detection.utils import ops as utils_ops
if StrictVersion(tf.__version__) < StrictVersion('1.9.0'):
raise ImportError('Please upgrade your TensorFlow installation to v1.9.* or later!')
# This is needed to display the images.
%matplotlib inline
from object_detection.utils import label_map_util
from object_detection.utils import visualization_utils as vis_util
import math
import itertools
from itertools import compress
from PIL import Image, ImageDrawAhora mismo, ya podremos cargar nuestro modelo pre-entrenado. Simplemente debemos definir la ruta a nuestro modelo PATH_TO_FROZEN_GRAPH, y la ruta a las labels PATH_TO_LABELS.
# Model Name
MODEL_NAME = 'ssd_mobilenet_v2_coco_2018_03_29'
# Path to frozen detection graph. This is the actual model that is used for the object detection.
PATH_TO_FROZEN_GRAPH = "/gdrive/My Drive/Projects/Pedestrian_Detection
/models/research/pretrained_model/
ssd_mobilenet_v2_coco_2018_03_29/frozen_inference_graph.pb"
# List of the strings that is used to add correct label for each box.
PATH_TO_LABELS = '/gdrive/My Drive/Projects/Pedestrian_Detection
/models/research/object_detection/data/mscoco_label_map.pbtxt'
# Load graph
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_FROZEN_GRAPH, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
Debemos mapear los índices de las labels a los nombres de los objetos que nuestro modelo va a predecir. De esta forma, cuando nuestro modelo prediga 1 sabremos que corresponde a la etiqueta person. Aquí vamos a usar algunas funciones que nos proporciona TF pero podremos usar las nuestras propias.
category_index =
label_map_util.create_category_index_from_labelmap(PATH_TO_LABELS, use_display_name=True)
La función run_inference_for_single_image toma como argumentos la imagen y nuestro modelo, y nos devolverá la predicción. En concreto, devuelve un diccionario output_dict que contiene las coordenadas y la etiqueta para cada objecto que ha detectado en la imagen.
def run_inference_for_single_image(image, graph):
with graph.as_default():
with tf.Session() as sess:
# Get handles to input and output tensors
ops = tf.get_default_graph().get_operations()
all_tensor_names = {output.name for op in ops for output in op.outputs}
tensor_dict = {}
for key in [
'num_detections', 'detection_boxes', 'detection_scores',
'detection_classes', 'detection_masks'
]:
tensor_name = key + ':0'
if tensor_name in all_tensor_names:
tensor_dict[key] = tf.get_default_graph().get_tensor_by_name(tensor_name)
if 'detection_masks' in tensor_dict:
# The following processing is only for single image
detection_boxes = tf.squeeze(tensor_dict['detection_boxes'], [0])
detection_masks = tf.squeeze(tensor_dict['detection_masks'], [0])
# Reframe is required to translate mask from box coordinates to image coordinates and fit the image size.
real_num_detection = tf.cast(tensor_dict['num_detections'][0], tf.int32)
detection_boxes = tf.slice(detection_boxes, [0, 0], [real_num_detection, -1])
detection_masks = tf.slice(detection_masks, [0, 0, 0], [real_num_detection, -1, -1])
detection_masks_reframed = utils_ops.reframe_box_masks_to_image_masks(
detection_masks, detection_boxes, image.shape[0], image.shape[1])
detection_masks_reframed = tf.cast(
tf.greater(detection_masks_reframed, 0.5), tf.uint8)
# Follow the convention by adding back the batch dimension
tensor_dict['detection_masks'] = tf.expand_dims(
detection_masks_reframed, 0)
image_tensor = tf.get_default_graph().get_tensor_by_name('image_tensor:0')
# Run inference
output_dict = sess.run(tensor_dict,
feed_dict={image_tensor: np.expand_dims(image, 0)})
# all outputs are float32 numpy arrays, so convert types as appropriate
output_dict['num_detections'] = int(output_dict['num_detections'][0])
output_dict['detection_classes'] = output_dict[
'detection_classes'][0].astype(np.uint8)
output_dict['detection_boxes'] = output_dict['detection_boxes'][0]
output_dict['detection_scores'] = output_dict['detection_scores'][0]
if 'detection_masks' in output_dict:
output_dict['detection_masks'] = output_dict['detection_masks'][0]
return output_dictComo hemos dicho antes, nuestro modelo puede predecir diversos objetos al mismo tiempo (puedes verlos en category_index). Sin embargo, solo queremos mostrar una categoría en particular: person. Por tanto, hemos creado una función para filtrar nuestras predicciones en base a un threshold min_score y el id de la etiqueta categories. En este caso, el id para la etiqueta de personas es 1.
def filter_boxes(min_score, boxes, scores, classes, categories):
"""Return boxes with a confidence >= `min_score`"""
n = len(classes)
idxs = []
for i in range(n):
if classes[i] in categories and scores[i] >= min_score:
idxs.append(i)
filtered_boxes = boxes[idxs, ...]
filtered_scores = scores[idxs, ...]
filtered_classes = classes[idxs, ...]
return filtered_boxes, filtered_scores, filtered_classesMidiendo la distancia entre los objetos ?️
En este punto, tenemos ya un modelo preparado para ejecutar predicciones, el cual nos devuelve un diccionario output_dict con las coordenadas de los objetos. Queremos medir la distancia entre los objetos detectados por el modelo pero no es una solución trivial. Por tanto, hemos creado algunas funciones para calcular dicha distancia entre los centroides de cada objeto. Los pasos que sigue el código son:
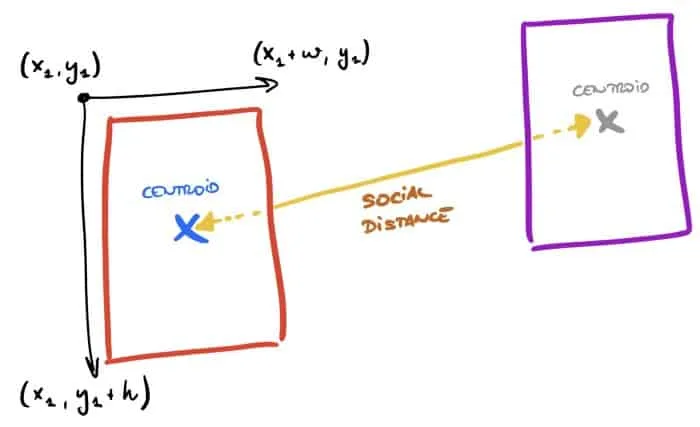
- Obtener las coordenadas de cada objeto usando la función calculate_coord.
- Calcular el centroide para cada rectángulo — calculate_centr.

-
- Debemos calcular todas las permutaciones entre los centroides usando calculate_perm.
- Calcular la distancia entre cada centroide (por ejemplo, entre person A y person B) con esta función: calculate_centr_distance.
- Finalmente, calcular el punto medio de cada segmento para visualizar la distancia como texto en la imagen — midpoint y calculate_slope.
def calculate_coord(bbox, width, height): """Return boxes coordinates""" xmin = bbox[1] * width ymin = bbox[0] * height xmax = bbox[3] * width ymax = bbox[2] * height return [xmin, ymin, xmax - xmin, ymax - ymin]
def calculate_centr(coord):
"""Calculate centroid for each box"""
return (coord[0]+(coord[2]/2), coord[1]+(coord[3]/2))
def calculate_centr_distances(centroid_1, centroid_2):
"""Calculate the distance between 2 centroids"""
return math.sqrt((centroid_2[0]-centroid_1[0])**2 + (centroid_2[1]-centroid_1[1])**2)
def calculate_perm(centroids):
"""Return all combinations of centroids"""
permutations = []
for current_permutation in itertools.permutations(centroids, 2):
if current_permutation[::-1] not in permutations:
permutations.append(current_permutation)
return permutations
def midpoint(p1, p2):
"""Midpoint between 2 points"""
return ((p1[0] + p2[0])/2, (p1[1] + p2[1])/2)
def calculate_slope(x1, y1, x2, y2):
"""Calculate slope"""
m = (y2-y1)/(x2-x1)
return mAhora que hemos definido estas funciones, podemos crear la función principal llamada show_inference el cual ejecutará la predicción para las imágenes y graficará los recuadros y las distancias entre los peatones.
La primera parte de esta función es responsable de obtener la imagen y ejecutar la inferencia. Obtendremos un diccionario output_dict con las coordenadas de los objetos que el modelo ha detectado.
image = Image.open(image_path)
# the array based representation of the image will be used later
image_np = load_image_into_numpy_array(image)
# Expanding dimensions
# Since the model expects images to have shape: [1, None, None, 3]
image_np_expanded = np.expand_dims(image_np, axis=0)
# Actual detection.
output_dict = run_inference_for_single_image(image_np, detection_graph)Seguidamente, definiremos un umbral confidence_cutoff=0.5 para evitar graficar predicciones con una probabilidad baja. En paralelo, obtendremos el tamaño de nuestra imagen y deberemos definir una relación “pixel-metro” para calcular la distancia correctamente. He analizado algunas imágenes y he considerado que width — 150px = 7 meters es una buena relación. Esta parte es complicada porque no tenemos en cuenta la perspectiva ni el ángulo de la cámara, es un problema complicado de generalizar para todas las imágenes y os animo a mejorarlo y mostrar vuestra solución con nosotros ?.
# Get boxes only for person
confidence_cutoff = 0.5
boxes, scores, classes = filter_boxes(confidence_cutoff, output_dict['detection_boxes'], output_dict['detection_scores'], output_dict['detection_classes'], [1])
# Get width and heigth
im = Image.fromarray(image_np)
width, height = im.size
# Pixel per meters - THIS IS A REFERENCE, YOU HAVE TO ADAPT THIS FOR EACH IMAGE
# In this case, we are considering that (width - 150) approximately is 7 meters
average_px_meter = (width-150) / 7
Finalmente, podemos calcular todos los centroides para nuestras predicciones y generar las combinaciones entre ellos. Posteriormente, podremos crear las líneas dx,dy que conectan los centroides y graficar la distancia.
# Calculate normalized coordinates for boxes
centroids = []
coordinates = []
for box in boxes:
coord = calculate_coord(box, width, height)
centr = calculate_centr(coord)
centroids.append(centr)
coordinates.append(coord)
# Calculate all permutations
permutations = calculate_perm(centroids)
# Display boxes and centroids
fig, ax = plt.subplots(figsize = (20,12), dpi = 90)
ax.imshow(image, interpolation='nearest')
for coord, centr in zip(coordinates, centroids):
ax.add_patch(patches.Rectangle((coord[0], coord[1]), coord[2], coord[3], linewidth=2, edgecolor='y', facecolor='none', zorder=10))
ax.add_patch(patches.Circle((centr[0], centr[1]), 3, color='yellow', zorder=20))
# Display lines between centroids
for perm in permutations:
dist = calculate_centr_distances(perm[0], perm[1])
dist_m = dist/average_px_meter
print("M meters: ", dist_m)
middle = midpoint(perm[0], perm[1])
print("Middle point", middle)
x1 = perm[0][0]
x2 = perm[1][0]
y1 = perm[0][1]
y2 = perm[1][1]
slope = calculate_slope(x1, y1, x2, y2)
dy = math.sqrt(3**2/(slope**2+1))
dx = -slope*dyEn resumen, la función debería quedar tal que así:
import matplotlib.pyplot as plt
import matplotlib.patches as patches
from random import randrange
# If you want to test the code with your images, just add path to the images to the TEST_IMAGE_PATHS.
PATH_TO_TEST_IMAGES_DIR = '/gdrive/My Drive/Projects/Pedestrian_Detection/
models/research/test_images'
TEST_IMAGE_PATHS = [ os.path.join(PATH_TO_TEST_IMAGES_DIR,
'image{}.jpg'.format(i)) for i in range(8, 9) ]
# Size, in inches, of the output images.
IMAGE_SIZE = (12, 8)
def show_inference(image_path):
image = Image.open(image_path)
# the array based representation of the image will be used later in order to prepare the
# result image with boxes and labels on it.
image_np = load_image_into_numpy_array(image)
# Expand dimensions since the model expects images to have shape: [1, None, None, 3]
image_np_expanded = np.expand_dims(image_np, axis=0)
# Actual detection.
output_dict = run_inference_for_single_image(image_np, detection_graph)
# Get boxes only for person
confidence_cutoff = 0.5
boxes, scores, classes = filter_boxes(confidence_cutoff,
output_dict['detection_boxes'], output_dict['detection_scores'],
output_dict['detection_classes'], [1])
# Get width and heigth
im = Image.fromarray(image_np)
width, height = im.size
# Pixel per meters - THIS IS A REFERENCE, YOU HAVE TO ADAPT THIS FOR EACH IMAGE
# In this case, we are considering that (width - 150) approximately is 7 meters
average_px_meter = (width-150) / 7
# Calculate normalized coordinates for boxes
centroids = []
coordinates = []
for box in boxes:
coord = calculate_coord(box, width, height)
centr = calculate_centr(coord)
centroids.append(centr)
coordinates.append(coord)
# Calculate all permutations
permutations = calculate_perm(centroids)
# Display boxes and centroids
fig, ax = plt.subplots(figsize = (20,12), dpi = 90)
ax.imshow(image, interpolation='nearest')
for coord, centr in zip(coordinates, centroids):
ax.add_patch(patches.Rectangle((coord[0], coord[1]), coord[2], coord[3], linewidth=2, edgecolor='y', facecolor='none', zorder=10))
ax.add_patch(patches.Circle((centr[0], centr[1]), 3, color='yellow', zorder=20))
# Display lines between centroids for perm in permutations:
dist = calculate_centr_distances(perm[0], perm[1])
dist_m = dist/average_px_meter
print("M meters: ", dist_m)
middle = midpoint(perm[0], perm[1])
print("Middle point", middle)
x1 = perm[0][0]
x2 = perm[1][0]
y1 = perm[0][1]
y2 = perm[1][1]
slope = calculate_slope(x1, y1, x2, y2)
dy = math.sqrt(3**2/(slope**2+1))
dx = -slope*dy
# Display randomly the position of our distance text
if randrange(10) % 2== 0:
Dx = middle[0] - dx*10
Dy = middle[1] - dy*10
else:
Dx = middle[0] + dx*10
Dy = middle[1] + dy*10
if dist_m < 1.5:
ax.annotate("{}m".format(round(dist_m, 2)), xy=middle, color='white', xytext=(Dx, Dy), fontsize=10,
arrowprops=dict(arrowstyle='->', lw=1.5, color='yellow'), bbox=dict(facecolor='red', edgecolor='white', boxstyle='round', pad=0.2), zorder=30)
ax.plot((perm[0][0], perm[1][0]), (perm[0][1], perm[1][1]), linewidth=2, color='yellow', zorder=15) elif 1.5 < dist_m < 3.5:
ax.annotate("{}m".format(round(dist_m, 2)), xy=middle, color='black', xytext=(Dx, Dy), fontsize=8,
arrowprops=dict(arrowstyle='->', lw=1.5, color='skyblue'), bbox=dict(facecolor='y', edgecolor='white', boxstyle='round', pad=0.2), zorder=30)
ax.plot((perm[0][0], perm[1][0]), (perm[0][1], perm[1][1]), linewidth=2, color='skyblue', zorder=15)
else:
pass
# Make prediction
for file in TEST_IMAGE_PATHS:
show_inference(file)Después de todo el trabajo, podremos correr nuestro código en imágenes. Simplemente debemos añadir las imágenes a esta carpeta: ../Projects/Pedestrian_Detection/models/research/test_images
_7coQNS7_14BXFUfCMphJF

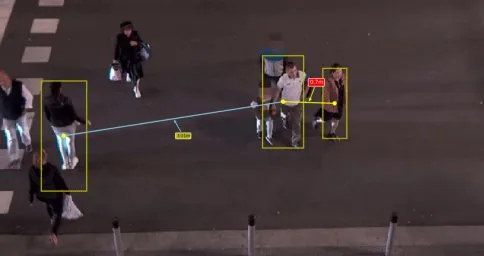
Wow! Tienen Buena pinta y podría incluso mejor si ejecutamos este código en videos. Así que, ¡vamos allá!
Predicción en vídeos
El código para ejecutar el modelo en vídeos es igual que para las imágenes porque usaremos OpenCV para dividir el video en frames y así poder procesar cada frame como imágenes individuales.
import cv2
import matplotlib
from matplotlib import pyplot as plt
plt.ioff()matplotlib.use('Agg')
FILE_OUTPUT = '/gdrive/My Drive/Projects/Pedestrian_Detection/models/research/test_
images/Rail_Station_Predicted2.mp4'
# Playing video from file
cap = cv2.VideoCapture('/gdrive/My Drive/Projects/Pedestrian_Detection/
models/research/test_images/Rail_Station_Converted.mp4')
# Default resolutions of the frame are obtained.The default resolutions are system dependent.
# We convert the resolutions from float to integer.
width = int(cap.get(3))
height = int(cap.get(4))
dim = (width, height)
print(dim)
tope = 10
i = 0
new = True
with detection_graph.as_default():
with tf.Session(graph=detection_graph) as sess:
# Definite input and output Tensors for detection_graph
image_tensor = detection_graph.get_tensor_by_name('image_tensor:0')
# Each box represents a part of the image where a particular object was detected.
detection_boxes = detection_graph.get_tensor_by_name('detection_boxes:0')
# Each score represent how level of confidence for each of the objects.
# Score is shown on the result image, together with the class label.
detection_scores =
detection_graph.get_tensor_by_name('detection_scores:0')
detection_classes =
detection_graph.get_tensor_by_name('detection_classes:0')
num_detections =
detection_graph.get_tensor_by_name('num_detections:0')
i = 0
while(cap.isOpened()):
# Capture frame-by-frame
ret, frame = cap.read()
if ret == True:
# Correct color
frame = gray = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# Expand dimensions since the model expects images to have shape: [1, None, None, 3]
image_np_expanded = np.expand_dims(frame, axis=0)
# Actual detection.
(boxes, scores, classes, num) = sess.run(
[detection_boxes, detection_scores, detection_classes, num_detections],
feed_dict={image_tensor: image_np_expanded})
# Filter boxes
confidence_cutoff = 0.5
boxes, scores, classes = filter_boxes(confidence_cutoff,
np.squeeze(boxes), np.squeeze(scores), np.squeeze(classes), [1])
# Calculate normalized coordinates for boxes
centroids = []
coordinates = []
for box in boxes:
coord = calculate_coord(box, width, height)
centr = calculate_centr(coord)
centroids.append(centr)
coordinates.append(coord)
# Pixel per meters
average_px_meter = (width-150) / 7
permutations = calculate_perm(centroids)
# Display boxes and centroids
fig, ax = plt.subplots(figsize = (20,12), dpi = 90, frameon=False)
ax = fig.add_axes([0, 0, 1, 1])
ax.axis('off')
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.spines['bottom'].set_visible(False)
ax.spines['left'].set_visible(False)
ax.get_xaxis().set_ticks([])
ax.get_yaxis().set_ticks([])
for coord, centr in zip(coordinates, centroids):
ax.add_patch(patches.Rectangle((coord[0], coord[1]),
coord[2], coord[3], linewidth=2, edgecolor='y', facecolor='none', zorder=10))
ax.add_patch(patches.Circle((centr[0], centr[1]), 3,
color='yellow', zorder=20))
# Display lines between centroids
for perm in permutations:
dist = calculate_centr_distances(perm[0], perm[1])
dist_m = dist/average_px_meter
x1 = perm[0][0]
y1 = perm[0][1]
x2 = perm[1][0]
y2 = perm[1][1]
# Calculate middle point
middle = midpoint(perm[0], perm[1])
# Calculate slope
slope = calculate_slope(x1, y1, x2, y2)
dy = math.sqrt(3**2/(slope**2+1))
dx = -slope*dy
# Set random location
if randrange(10) % 2== 0:
Dx = middle[0] - dx*10
Dy = middle[1] - dy*10
else:
Dx = middle[0] + dx*10
Dy = middle[1] + dy*10
if dist_m < 1.5:
ax.annotate("{}m".format(round(dist_m, 2)), xy=middle,
color='white', xytext=(Dx, Dy), fontsize=10, arrowprops=dict(arrowstyle='->',
lw=1.5, color='yellow'), bbox=dict(facecolor='red', edgecolor='white',
boxstyle='round', pad=0.2), zorder=35)
ax.plot((perm[0][0], perm[1][0]), (perm[0][1], perm[1][1]),
linewidth=2, color='yellow', zorder=15)
elif 1.5 < dist_m < 3.5:
ax.annotate("{}m".format(round(dist_m, 2)), xy=middle,
color='black', xytext=(Dx, Dy), fontsize=8, arrowprops=dict(arrowstyle='->',
lw=1.5, color='skyblue'), bbox=dict(facecolor='y', edgecolor='white',
boxstyle='round', pad=0.2), zorder=35)
ax.plot((perm[0][0], perm[1][0]), (perm[0][1], perm[1][1]),
linewidth=2, color='skyblue', zorder=15)
else:
pass
ax.imshow(frame, interpolation='nearest')
# This allows you to save each frame in a folder
#fig.savefig("/gdrive/My
Drive/Projects/Pedestrian_Detection/models/research/test_images/TEST_{}.png".
format(i))
# i += 1
# Convert figure to numpy
fig.canvas.draw()
img = np.fromstring(fig.canvas.tostring_rgb(), dtype=np.uint8,
sep='')
img = img.reshape(fig.canvas.get_width_height()[::-1] + (3,))
img = np.array(fig.canvas.get_renderer()._renderer)
img = cv2.cvtColor(img,cv2.COLOR_RGB2BGR)
if new:
print("Define out")
out = cv2.VideoWriter(FILE_OUTPUT,
cv2.VideoWriter_fourcc(*'MP4V'), 20.0, (img.shape[1], img.shape[0]))
new = False
out.write(img)
else:
break
# When everything done, release the video capture and video write objects
cap.release()
out.release()
# Closes all the frames
cv2.destroyAllWindows()
Como hicimos antes, simplemente debemos copiar nuestro video en: ../Projects/Pedestrian_Detection/models/research/test_images y actualizar el path en cap = cv2.VideoCapture(…).También podemos definir un nombre para FILE_OUTPUT.
