
Este proyecto aplica técnicas de Data Science e Inteligencia Artificial para transformar la forma en que los usuarios descubren contenido.
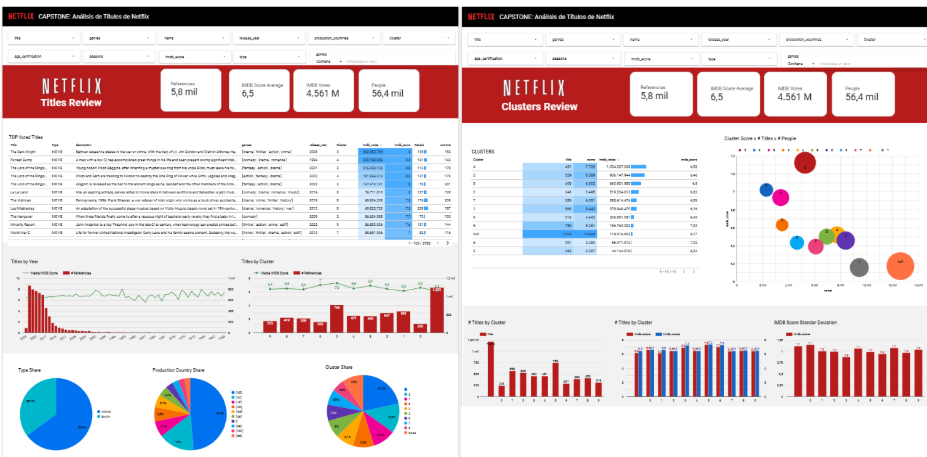
A partir del catálogo de Netflix, se realiza un análisis exploratorio y una clusterización mediante algoritmos de aprendizaje no supervisado, agrupando películas y series según similitudes en género, temática y valoración.
Realizado por Arnaud Chafai | Alfonso Gragera | Miguel Ángel Rojo
Titulación Máster en IA & Data Science
Herramientas Python | HTML | CSS | Pandas | NumPy | Scikit-learn | Scikit-learn | Matplotlib | Seaborn | Beautiful Soup | Selenium | OpenAI API
⭐Best Capstone Award 2025
Objetivos
La motivación de este proyecto es demostrar cómo la Inteligencia Artificial y la Ciencia de Datos pueden potenciar las plataformas de streaming, ofreciendo experiencias más personalizadas y relevantes para el usuario.
Mediante el uso de Machine Learning y Procesamiento de Lenguaje Natural, se busca:
- Incrementar el engagement
- Prolongar el tiempo de visualización
- Maximizar el LifeTime Value
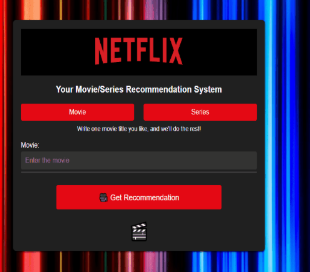
¿Cómo funciona?
El sistema permite al usuario introducir el título de una producción que le gusta y, como resultado, recibe recomendaciones personalizadas acompañadas de un breve resumen, puntos fuertes destacados y posibles debilidades.
El objetivo es ofrecer una experiencia de recomendación más precisa, transparente y enriquecedora.
La recomendación de contenidos se convierte en una poderosa herramienta estratégica para fidelizar y mantener conectados a los usuarios.
